AWS Region tells the physical location around the globe where AWS data centres are located. Data centres mean physical location that stores the computing machines and related hardware equipment – like everything about the computing infrastructure required to build an IT system such as Computing Servers, data storage drives, networking hardware equipment – routers, switches, firewalls etc. Within one geographic area, every AWS Region comprises of minimum of three, physically separate, isolated Availability Zones (AZs). AWS keeps multiple geographic Regions to server customers anywhere in the world providing extensive global footprint. It includes Regions in North America, South America, Europe, China, Asia Pacific, South Africa, and the Middle East etc.
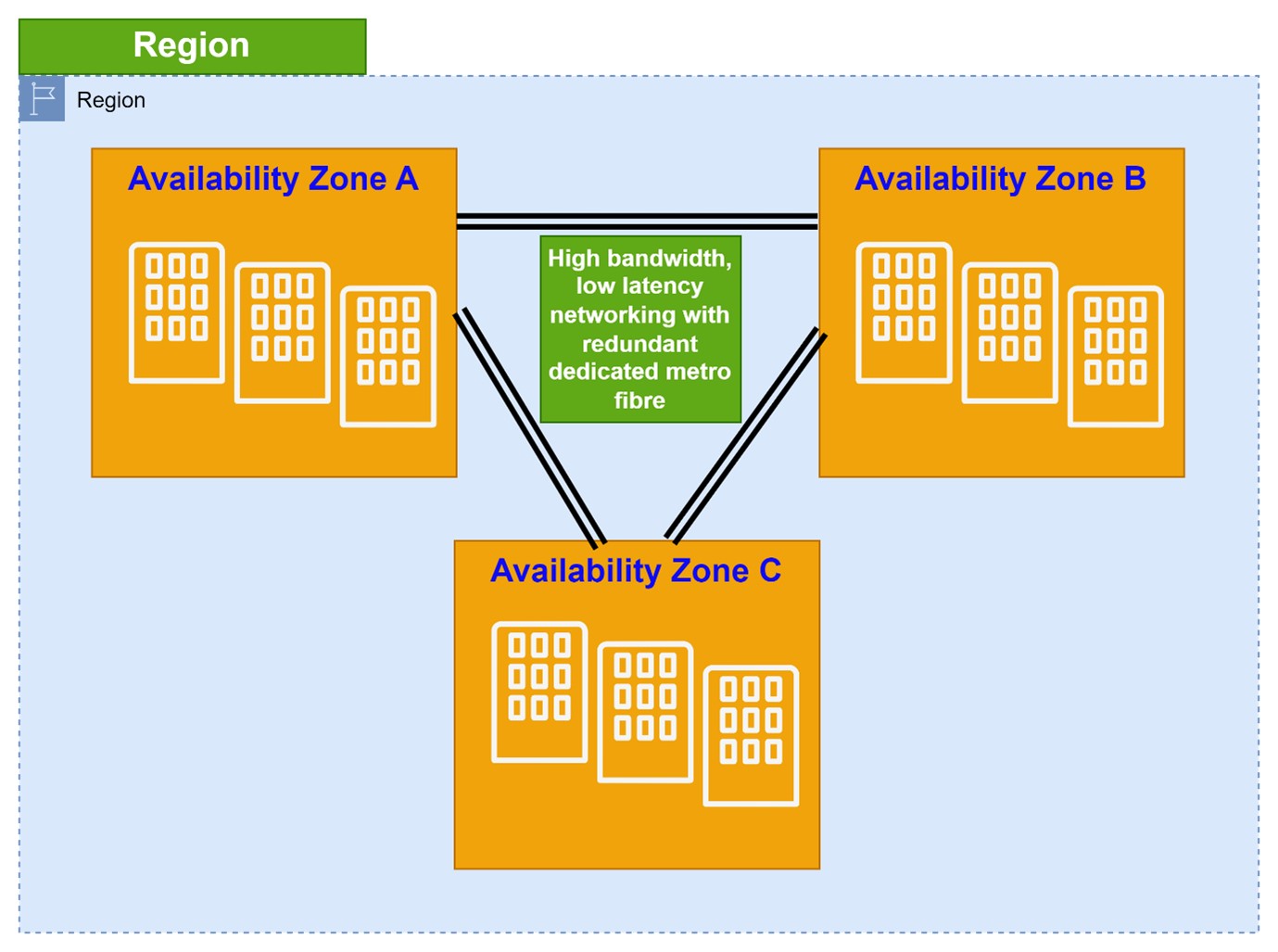
Each Availability Zone (AZ) has one or more data centres. AZs in a region are inter-connected with each other via low-latency fibre networks. Each AZ has its own power, cooling, and physical security. AZs are physically separated from each other by few kilometers but all AZs are within 100 km in a region.
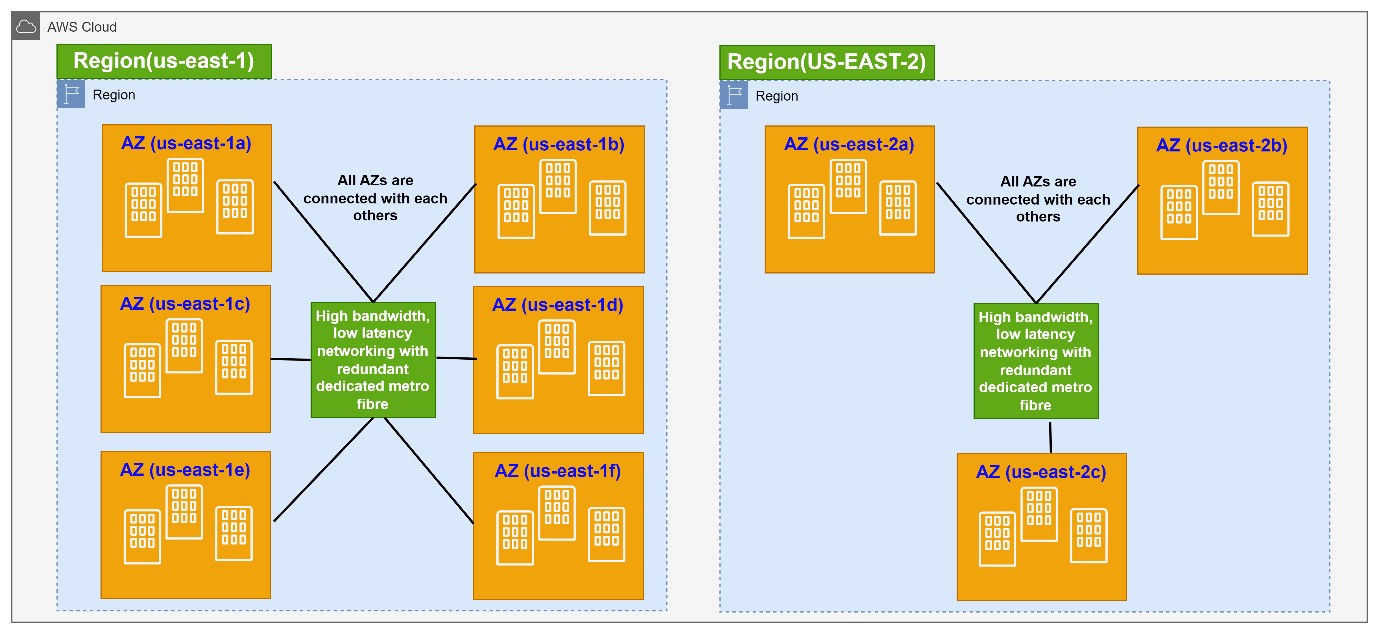
Below picture shows 2 regions – us-east-1(N Virginia) and us-east-2(Ohio). The us-east-1 region contains 6 AZs (us-east-1a, us-east-1b, us-east-1c, us-east-1d, us-east-1e, us-east-1f) and us-east-2 contains 3 AZs (us-east-2a, us-east-2b, us-east-2c).
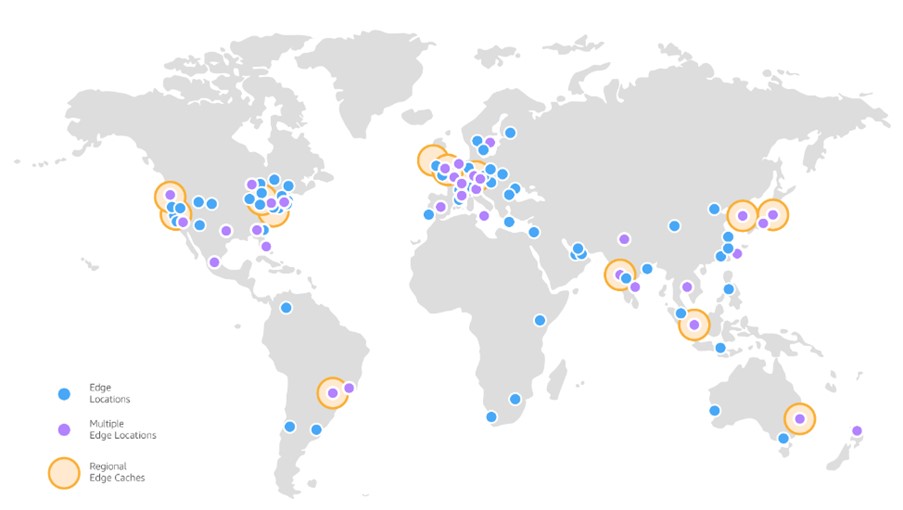
In addition to AWS Region and Availability Zones, AWS also has Global Edge Network which contains 550+ Edge Locations, 23 regional edge caches in 100+ cities across 50 countries to deliver contents to users with low latency and high transfer speeds. Let us understand it. For example, one US organization delivers video contents to its customers and the contents are hosted in us-east-1 region. Organizations have the customer presence globally. Now if any user from Mumbai location wants to watch the video, the traffic will from Mumbai to US and which won’t be an effective solution to deliver content in high speed. To alleviate this problem, AWS has brought the concept of Edge Locations which are small data centres located closed to user’s location (here it is near Mumbai) and contents are copied into the nearest Edge locations and user can watch the video directly from the closet Edge location with lower latency.
This image is taken from Amazon Web Services documentation.
AWS Edge Locations run AWS CloudFront which is a Content Delivery Network (CDN) service to deliver content to users with high transfer speeds and low latency from its closest network point minimizing network hops.
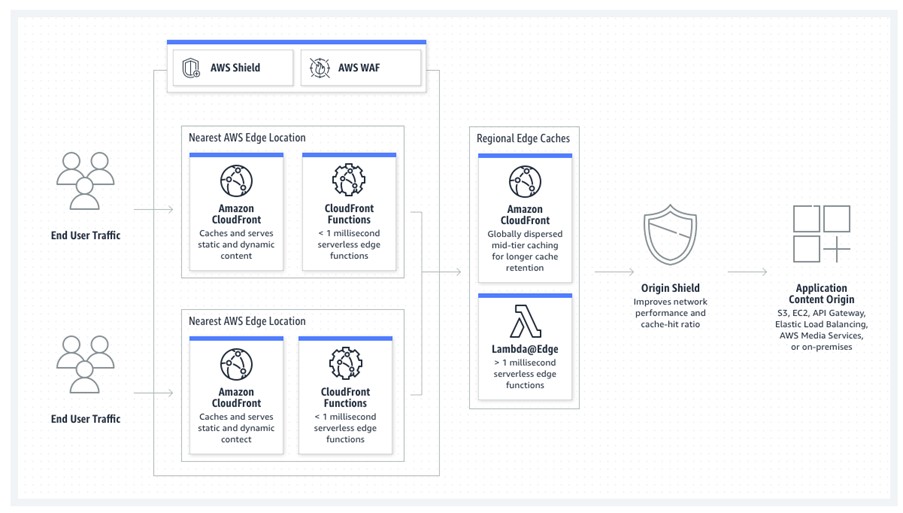
This image is taken from Amazon Web Services documentation.
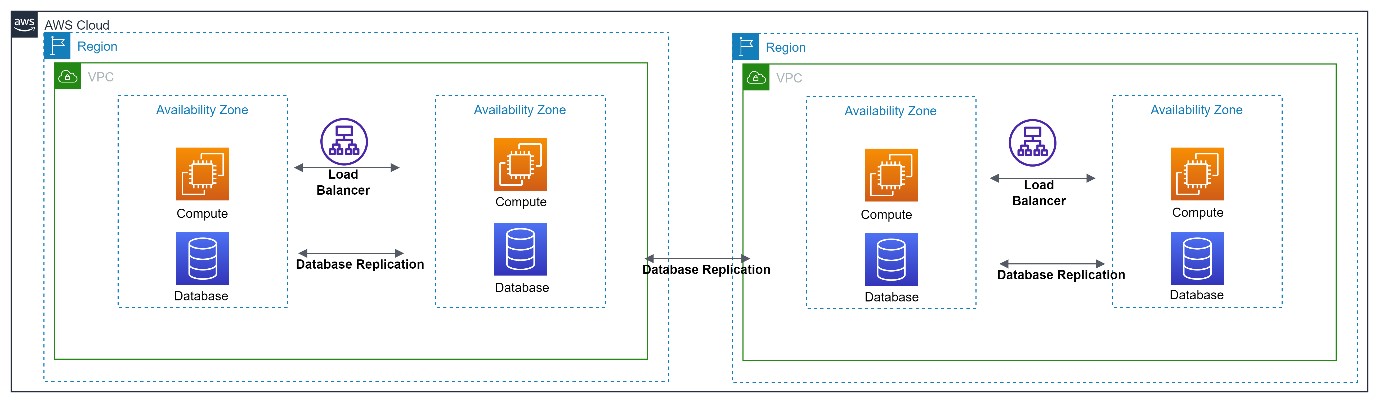
High Availability of applications can be achieved by configuring the resource pools into multiple availability zones having data replication, load balancing and automatic failover stitched together – so the application will remain resilient to zonal failures.
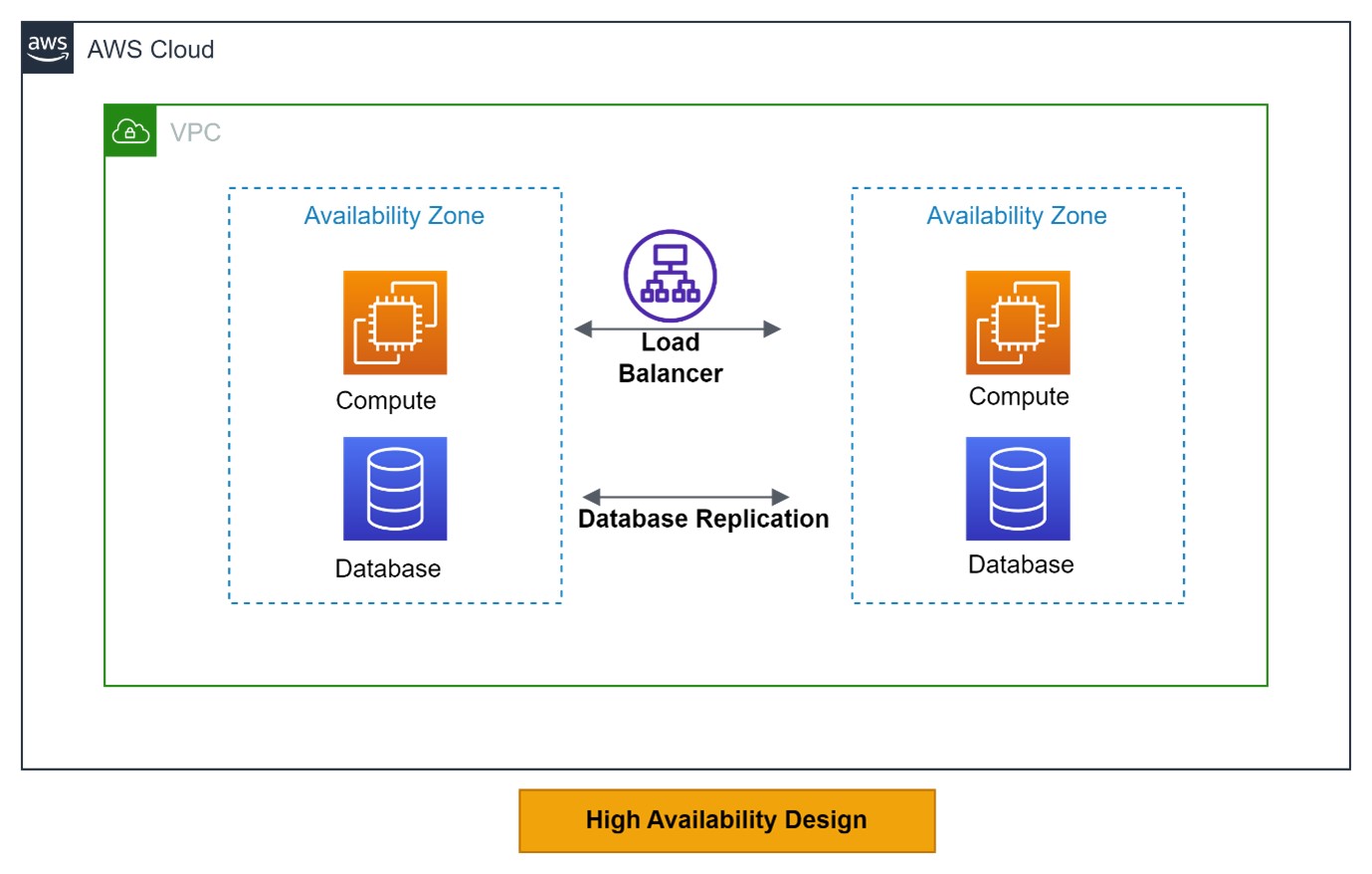
Disaster Recovery defines an organization’s capability to regain its access and business functionality of the IT infrastructure post the disaster event like natural calamities – storms, floods, earthquakes etc. or political unrest etc.
Disaster Recover site is designed as a secondary location where organization restores the business-critical IT infrastructure, services, or applications when the primary site is down due to disaster.
AWS resources are configured cross-region so business system is protected as in the event of disaster, it can switch from primary region (affected region) to secondary region (alternate). Primary and Secondary regions are far apart physically so disaster cannot impact both at the same time.
Business objectives are defined for DR with RTO (Recovery Time Objective) and RPO (Recovery Point Objective).
DR strategy varies business-wise based on its need and criticality. Based on the DR strategy, infrastructure tasks in DR region are different and cost is also variable.
| RTO | RPO | Recovery Option | Cost | DR Tasks |
|---|---|---|---|---|
| Hours | less than 24 Hours | Backup & restore | Low | Perform Resource provisioning for all applications into DR region and restore the database from the snapshot. |
| Tens of minutes | Tens of minutes | Pilot Light | Medium | Maintain copy of infrastructure resource in the DR region, keep both primary and DR region up to date deploying all changes in parallel – both application and infrastructure changes. Do not run the apps in DR region. Only Provision resources in DR region during failover and testing event. Always replicate data from primary to DR region and keep both the DBs in both regions always on and DR database must be synchronized with primary database. |
| Minutes | Minutes | Warm standby | High | Provision exact copy of the entire infrastructure into the DR region and keep apps running in limited numbers to accept smaller volume of traffic than Primary region. This is to ensure that during disaster, the DR site will be operational as quickly as everything is up and running there with scaled down mode. It will be fully operation once the actual traffic is turned on from primary to DR. |
| Near Zero | Zero or near zero | Multi-site or Active-active | Higher | Provision exact copy of the entire infrastructure into the DR region and keep apps running in same way as Primary to accept similar volume of traffic as Primary region. |